Reliable Multi-lingual and Cross-lingual Open Data Exploration in Natural Language (MuLi)
Result
Scientific Contribution:
A major outcome of the project is the development of XMODE, a novel LLM-based agent system for explainable, multi-modal data exploration. The results were documented in the paper "Explainable Multi‑Modal Data Exploration in Natural Language via LLM Agent" (see Link below the text).
Follow-up Research and Proposal Development:
Insights and technological components from the project have been directly leveraged in the preparation of a successful Horizon Europe funding proposal: DataGEMS – Data Discovery Platform with Generalized Exploratory, Management, and Search Capabilities (see link below the text). The project focuses on expanding multi-modal data discovery using AI across domains such as education, linguistics, and meteorology.
Description
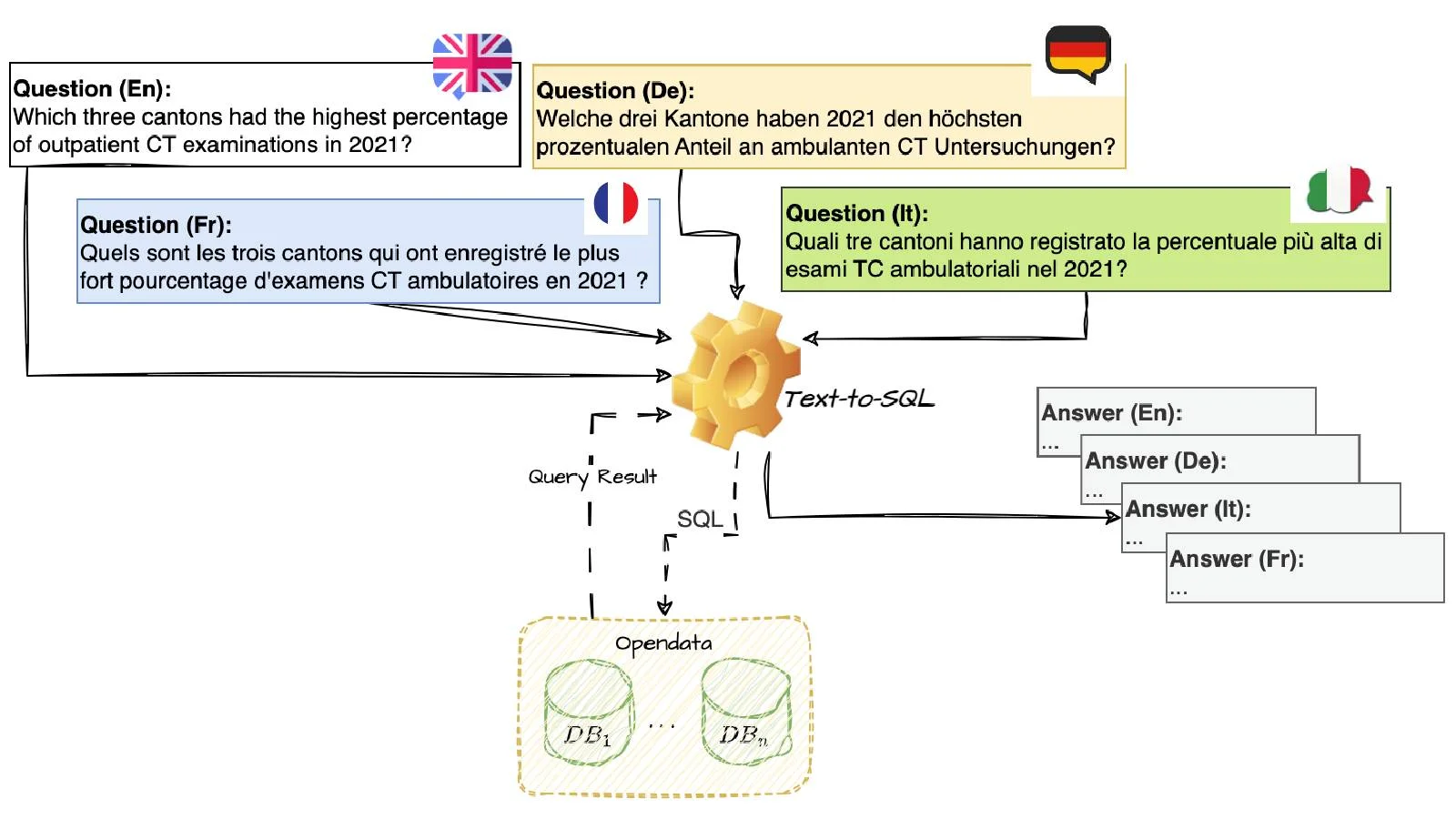
As data consolidates into relational databases, the need for text-to-SQL systems grows, democratizing access to information by allowing natural language queries. The potential for improvements brought by Large Language Models (LLMs) in text-to-SQL systems is mostly assessed on monolingual English datasets. However, their performance and robustness with respect to other languages remain vastly unexplored.
In this project, we would like to concentrate on a multi-lingual and cross-lingual benchmark for evaluating text-to-SQL systems based on real-world applications. This dataset will comprise natural language/SQL-pairs over big databases with varying levels of complexity for English, German, French, and Italian. We will assess robustness of current state-of-the-art text-to-SQL models, particularly in handling diverse languages such as German, French, and Italian. We aim to address the challenges of achieving fairness in multiple languages, initiating discussions to develop more reliable text-to-SQL systems tailored for multi-lingual environments.
Key data
Projectlead
Co-Projectlead
Project team
Project status
completed, 08/2024 - 07/2025
Institute/Centre
Institute of Computer Science (InIT)
Funding partner
Hasler Stiftung
Project budget
48'000 CHF
Further documents and links

Obere Kirchgasse 2 / Steinberggasse 12/14
8400 Winterthur