ZHAW-Forschende entwickeln datenzentrierten KI-Trick zur Bereinigung von Maschinendaten
Forschende der ZHAW School of Engineering haben ein innovatives Framework entwickelt, das Anomalien und Defekte in Maschinen effizienter erkennt, selbst wenn Trainingsdaten verunreinigt sind. Diese Entwicklung geht auf eine zentrale Herausforderung in der KI-Forschung ein: eine präzise Fehlererkennung, ohne auf fehlerfreie Trainingsdaten zurückgreifen zu können.

Die Erkennung ungewöhnlicher oder anormaler Muster in industriellen Daten ist eine der häufigsten Aufgaben von KI-Algorithmen in kommerziellen Anwendungen. Sie ermöglicht die frühzeitige Erkennung von Degradation, Defekten und Fehlern in der Produktion und erlaubt es, diese Probleme rechtzeitig zu beheben und so Kosten zu sparen und Ausfallzeiten zu reduzieren.
Anomalieerkennung in Maschinen basiert in der Regel auf „Lernen aus der Normalität“. Das bedeutet, dass KI-Algorithmen anhand von Daten aus einwandfrei funktionierenden Maschinen trainiert werden, um später Abweichungen in Betriebsdaten zu erkennen. In der Praxis stehen jedoch häufig keine vollständig fehlerfreien Daten zur Verfügung, was die Effektivität der Modelle erheblich beeinträchtigt. Das Training mit kontaminierten Daten führt dazu, dass die Modelle nicht mehr zwischen normalen und fehlerhaften Betriebsbedingungen unterscheiden können – eine Herausforderung, die bislang kaum von der Forschung gelöst werden konnte.
Einsatz von KI-Algorithmen ohne menschliche Eingriffe
«Durch die Zusammenarbeit mit verschiedenen Unternehmen haben wir realisiert, dass es einen Bedarf an KI-Algorithmen gibt, die direkt und ohne vorherige menschliche Eingriffe für die Datenbeschriftung eingesetzt werden können», erklärt Dr. Lilach Goren Huber vom Smart Maintenance Team am ZHAW Institut für Datenanalyse und Prozessdesign (IDP).
Neues Framework zur unüberwachten Datenverfeinerung
Um diese Lücke zu schliessen, haben die ZHAW-Forschenden ein neuartiges Framework entwickelt, das historische, potenziell kontaminierte Daten automatisch auswertet und normal funktionierende Datenproben vollständig unüberwacht extrahiert. Auf diese Weise können die bereinigten Daten für das Training von Anomalieerkennungsalgorithmen genutzt werden, ohne dass eine aufwendige manuelle Sortierung nötig ist.
Einfaches Konzept, starke Wirkung
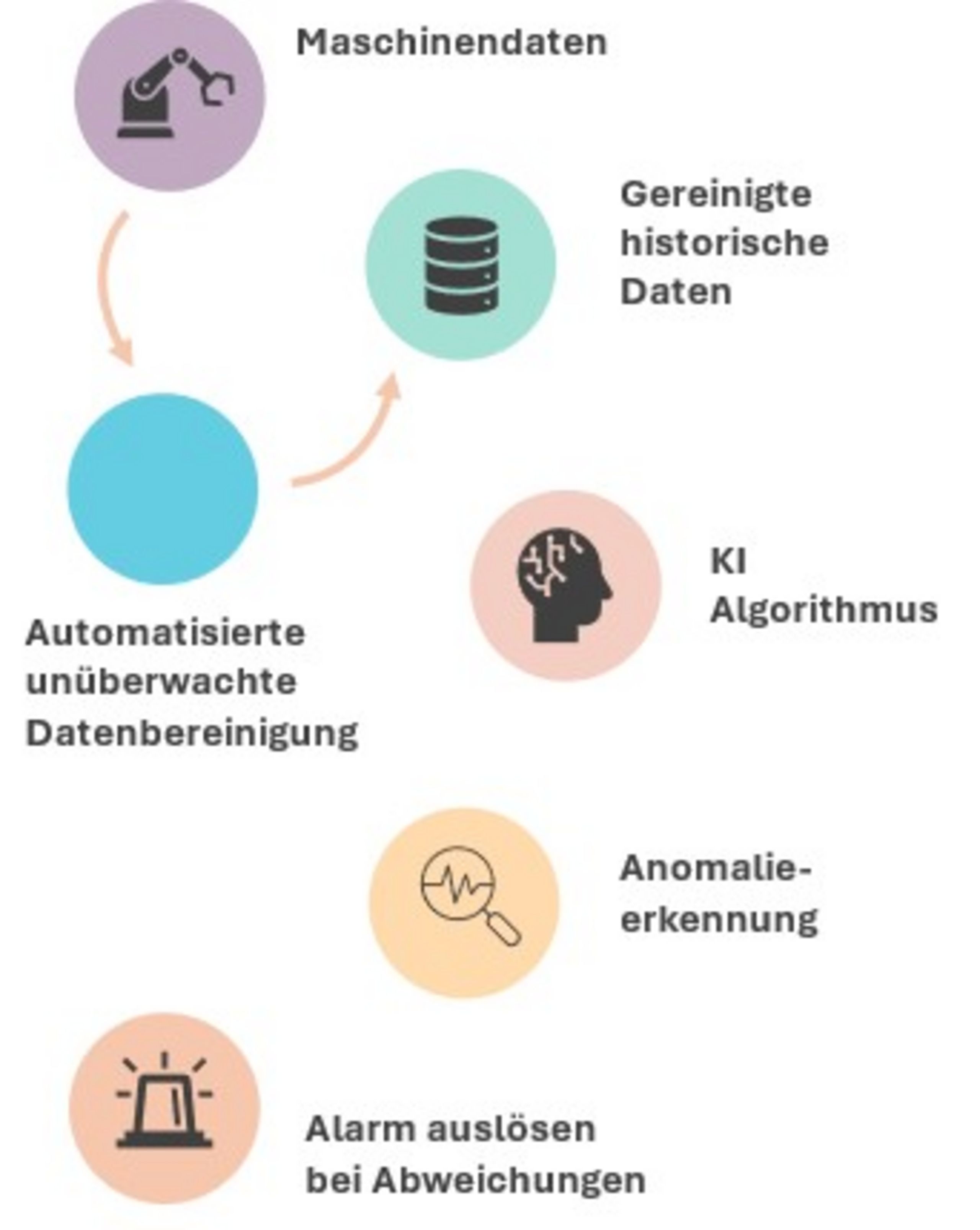
Das Framework basiert auf einer zentralen Beobachtung: Fehlerhafte Datenproben haben einen stärkeren Einfluss auf die Leistung der KI-Modelle als normale Proben. Basierend auf diesem Prinzip wird jeder Datenprobe ein Score zugewiesen, der ihren Einfluss auf das Training misst. Proben mit einem hohen Score werden als potenziell fehlerhaft identifiziert und aus den Trainingsdaten entfernt. In Tests erzielte das Framework mit diesen verfeinerten Daten eine vergleichbare Leistung wie manuell bereinigte Datensätze.
Erfolgreiche Anwendung und Perspektiven
Die ZHAW hat die Methode an einer Vielzahl von Maschinentypen getestet, darunter Pumpen, Ventile, Ventilatoren und Triebwerke, und dabei vielversprechende Ergebnisse erzielt. In den meisten Fällen konnte das Framework den Mangel an fehlerfreien Trainingsdaten vollständig kompensieren. „Unser Ansatz ist nicht nur einfach und robust, sondern auch universell einsetzbar. Er kann mit beliebigen Datentypen und bestehenden Fehlererkennungsmethoden kombiniert werden“, erklärt Dr. Lilach Goren Huber.
Kontakt:
Dr. Lilach Goren Huber, ZHAW School of Engineering, Institut für Datenanalyse und Prozessdesign (IDP), Tel: +41 (0) 58 934 49 49, E-Mail: lilach.gorenhuber@zhaw.ch
David Bäuerle, ZHAW School of Engineering, Marketing und Kommunikation, Tel. +41 (0) 58 934 68 61, E-Mail david.baeuerle@zhaw.ch