Erstellt und bewertet die KI zukünftig Prüfungen an Universitäten?
ZHAW-Absolventen aus den Studiengängen Data Science und Informatik untersuchten in ihrer Bachelorarbeit die automatische Erstellung von offenen Prüfungsfragen und deren Bewertung. Sie evaluierten verschiedene automatische Bewertungssysteme und grosse Sprachmodelle (LLMs). Ihre Arbeit wird aktuell an der renommierten Computer Science Education Konferenz (SIGCSE 2024) in den USA vorgestellt. Wie schneiden die KI-Systeme im Vergleich zum Menschen ab?

Offene Fragen werden gegenüber geschlossenen Fragen oft bevorzugt, da sie in schriftlichen Prüfungen ein gründlicheres Verständnis des Lernstoffes überprüfen. Ihre Bewertung ist jedoch zeitintensiver und weniger objektiv als beispielsweise die Benotung von Multiple-Choice Antworten. Genau deshalb gibt es Bestrebungen, den Bewertungsprozess mit sogenannten Short Answer Grading (SAG)-Systemen zu automatisieren. Um die Fähigkeiten dieser Systeme beurteilen zu können, entwickelten die ZHAW-Studenten Gérôme Meyer und Philip Breuer unter der Leitung von Dr. Jonathan Fürst eine neue Benchmark.
Bewertung von Arbeiten: Mensch vs. Maschine
Die Arbeit wurde bei der Konferenz SIGCSE akzeptiert, die unter anderem von Google, Microsoft und der U.S. National Science Foundation unterstützt wird und sich mit Themen rund um den Informatikunterricht beschäftigt. Am 5. Dezember stellen die Bachelor-Absolventen ihre Vorarbeit vor, mit der sie den Vergleich von automatischen Bewertungssystemen erleichtern möchten. Darin kombinierten sie sieben häufig verwendete englische Datensätze, die insgesamt 19'000 Fragen, inklusive Antwort und Benotung, enthielten. Damit evaluierten sie eine Reihe aktueller SAG-Methoden. Es zeigte sich, dass KI-basierte Ansätze zwar vielversprechend, aber noch weit von der menschlichen Leistung entfernt sind. Die in der genaueren Analyse dieser Ergebnisse gewonnenen Erkenntnisse eröffnen neue Wege für die zukünftige Forschung an Mensch-Maschine-SAG-Systemen.
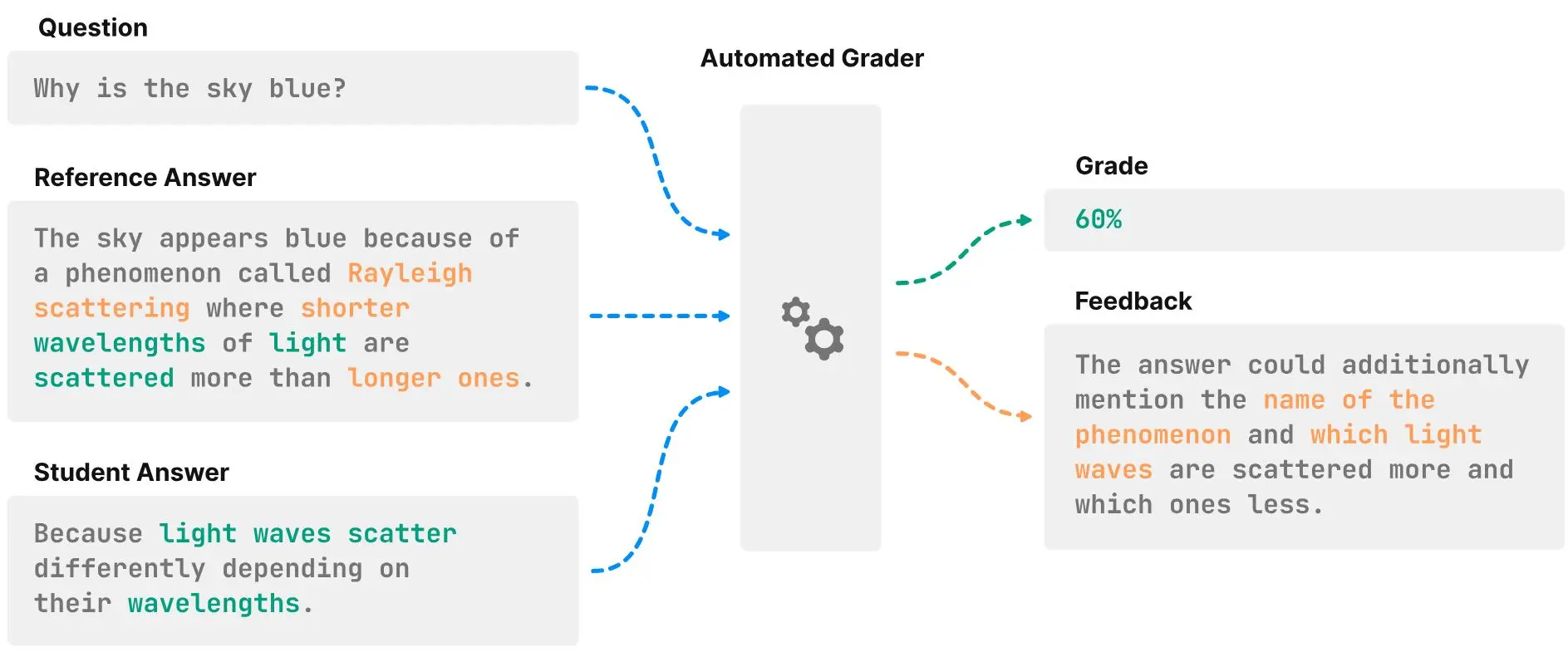

Zukünftige Fragestellungen
Weitere Erkenntnisse aus der Arbeit sind, dass Large Language Models (LLMs) auf diverse Situationen übertragbar sind und neue Fragen bewerten können. Spezialisierte Benotungssysteme haben damit grössere Schwierigkeiten – in diesen Fällen muss die KI «fine-getuned», also speziell trainiert werden. Ausserdem verbessert sich mit zunehmender Größe eines LLM die Fähigkeit zur Generalisierung. Die Studierenden möchten in einem nächsten Schritt Problematiken angehen, auf die sie während der Arbeit stiessen. So möchten sie die Benchmark in Zukunft mit vielfältigeren Datensätzen erweitern, um die negativen Effekte durch unausgeglichene Datensätze zu reduzieren, Mehrsprachigkeit mit einbeziehen und eine gründlichere Evaluierung automatischer Bewertungslösungen vornehmen.
Durch Forschungsarbeiten wie die von Gérôme Meyer und Philip Breuer erringen wir wichtige Erkenntnisse über die Möglichkeiten und Beschränkungen von KI in konkreten Anwendungen wie zum Beispiel in einem automatisierten Bewertungssystem - wie wir diese Anwendungen letztendlich einsetzen, liegt an uns Menschen.
Weitere Informationen
- Konferenz: ACM Virtual Global Computing Education Conference (SIGCSE VIRTUAL)
- Preprint: ASAG2024: A Combined Benchmark for Short Answer Grading
- Benchmark aus der Arbeit: ASAG2024