Anonymisierung von Daten
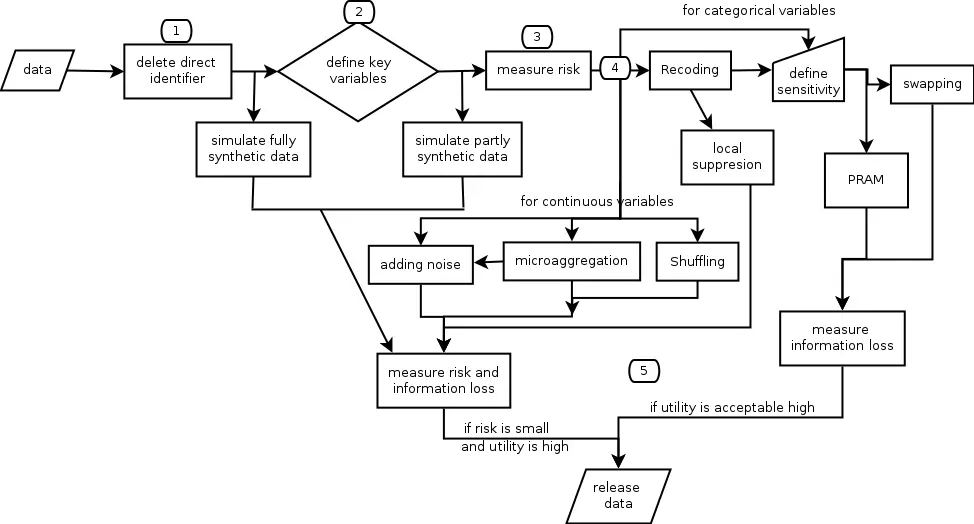
Für eine Datenweitergabe als auch für die interne Verwendung von Daten ist eine Anonymisierung erforderlich, sodass der Rückschluss auf Einzelpersonen verhindert wird und die Analysequalität der Daten aber möglichst erhalten bleibt. Die Datenanonymisierung wird auf komplexe Daten der Helsana angewendet.
Daten im Allgemeinen aber auch Daten der Helsana Gesundheitswissenschaften werden bei Analysen intern und extern zu weitreichenden Analysen verwendet. Auch zu Analysen für welche die Daten ursprünglich vielleicht gar nicht vorgesehen waren bzw. für das sie nicht gesammelt wurden.
Ganz zentral und in allen Punkten ist der Personenbezug das wesentliche Kriterium bei Entscheidung über angemessene Datenweitergabe und Datenanonymisierung. Daten ohne Personenbezug sind von den Datenschutzgesetzen ausgenommen und darum versucht man mit Anonymisierung den Personenbezug zu eleminieren.
Eine solche Anonymisierung ist keinesfalls durch perfekte IT-Sicherheit und Löschung oder Pseudoanonymisierung von direkten Identifizierungsvariablen, wie zum Beispiel Name des Versicherten und AHV-Nummer, ausreichend erfüllt, sobald Daten intern oder extern weiter gegeben werden. Die Gesetzgebung streicht seit circa zwei Jahrzehnten explizit heraus, dass die Löschung von direkten Identifizierungsvariablen (oder der Pseudoanonymisierung dieser) bei personenspezifischen Daten keineswegs ausreicht.
Zu allererst muss das Reidentifizierungsrisiko mit probabilistischen Ansätzen bestimmt werden. Entscheidend ist dann die Anwendung von Anonymisierungsmethoden so dass zugleich zwei Ziele erreicht werden: das Reidentifizierungsrisiko von Personen entscheidend zu verringern und die Datenanalysequalität der Daten nicht zu beeinträchtigen.
Die Daten enthalten Rechnungsinfos, Infos der Leistungserbringungen und Einzeldaten Versicherter als auch hochsensible Informationen.
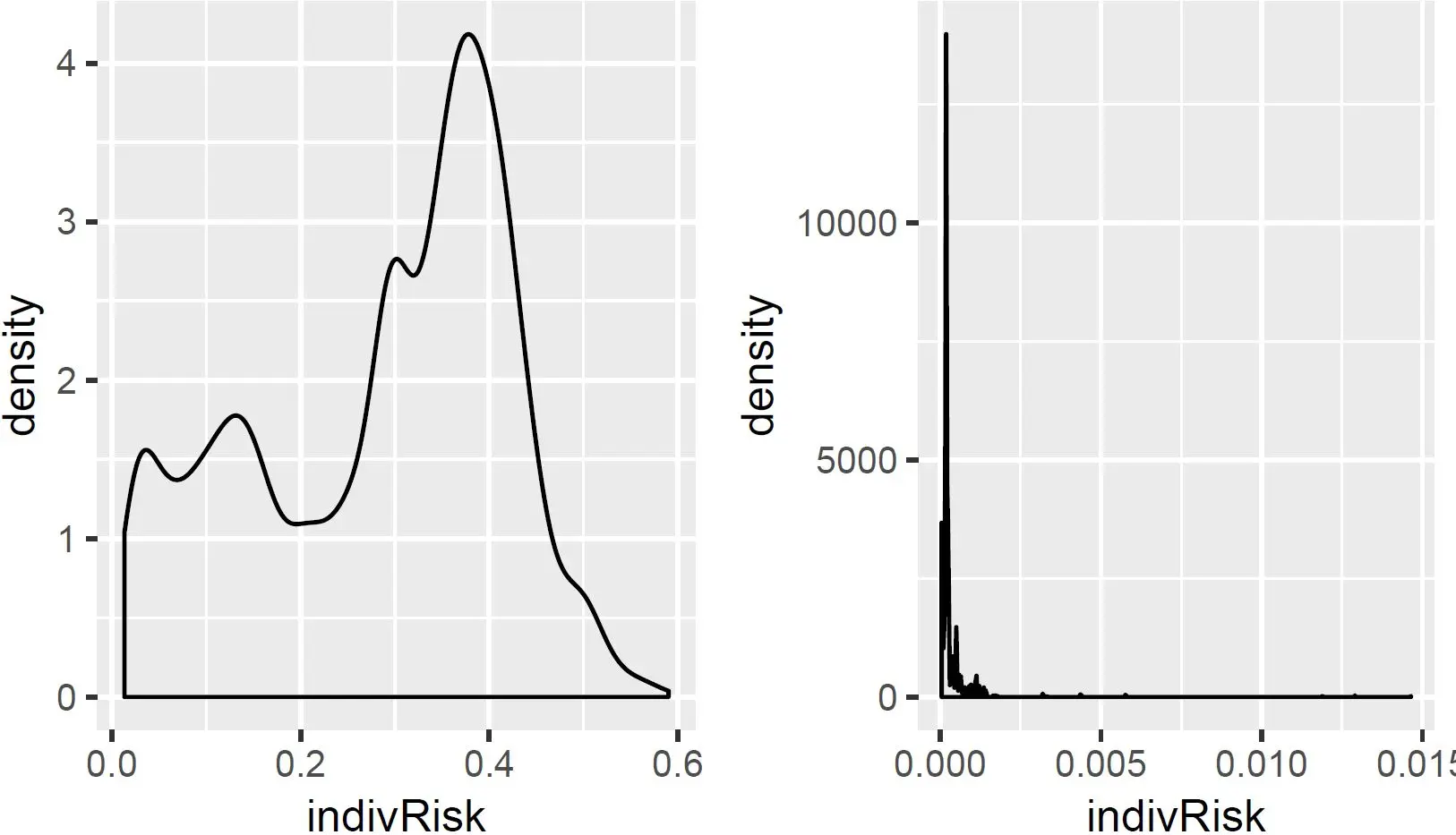
Grundsätzlich gilt, dass alle Empfänger von Daten der Helsana Zugriff auf öffentlich verfügbare Daten wie z.B. Statistiken (z.B. Bevölkerungsstatistik) und Metadaten (z.B. Raumgliederung BfS) haben. Alle Empfänger können sich auch (kostenpflichtig) Daten beschaffen, welche Merkmale Geschlecht, Alter und Wohnregion (Gemeinden) auf Personenebene aufweisen. Auch wird angenommen, dass Daten über Todestag und Kaufkraft (GFK) erhältlich sind, etc. Die Anzahl der Beobachtungen mit hohem Risiko ist bei pseudoanonymisierten Daten bei etwa 87%. Nach Anonymisierung ist das Risiko drastisch reduziert, siehe auch Abbildung 2.
Zur Anonymisierung wurde das R Paket sdcMicro (Templ, Meindl, Kowarik, 2015) verwendet.
Referenzen:
Templ, M. (2017). Statistical Disclosure Control for Micro-data Using the R Package sdcMicro, volume 67. Springer International Publishing.
Templ, M., Meindl, B., and Kowarik, A. (2015). Statistical disclosure control for micro-data using the R package sdcMicro. Journal of Statistical Software, 67(1):1–37.