Robuste und effiziente Methode für Objekterkennung auf Videostreams für die Intensivmedizin entwickelt
Forschung am CAI verbessert die Effizienz von Videoobjekterkennung deutlich und optimiert die Datenqualität für sensorgestützte Patientenüberwachung des Universitätsspitals Zürich
Robuste und effiziente Objekterkennungs­methode auf Videostreams für die Intensivmedizin entwickelt
Auf der Intensivstation werden Patienten kontinuierlich elektronisch überwacht, damit sofort alarmiert werden kann, wenn zum Beispiel ein Vitalparameter seinen Sollbereich verlässt. Auf der neurochirurgischen Intensivstation (NIPS) am Universitätsspital Zürich (USZ) ertönen durchschnittlich 700 Alarme pro Tag und Patient. Die hohe Anzahl von Alarmen beanspruchen dabei das medizinische Personal oft unnötig und binden wertvolle Zeit. Um die Belastung des Personals in Zukunft zu verringern, wurde am USZ eine IT-Infrastrukturen zur Aufzeichnung von Überwachungsdaten und zur Entwicklung von digitalen Systemen zur klinischen Unterstützung aufgebaut. Es zeigt sich jedoch, dass diese Systeme anfällig für Artefakte in den gemessenen Signalen sind, die durch die Bewegung des Patienten oder medizinische Interventionen verursacht werden können. Zudem sind solche Artefakte für sich genommen selbst für Menschen nur schwer von physiologischen Mustern zu unterscheiden. Viel einfacher ist es hingegen, wenn man sich direkt am Bett befindet und den Kontext sieht, in dem ein bestimmtes Signal gemessen wird.
Um genau diesen Kontext für die Erforschung und Entwicklung von zukünftigen Unterstützungssystemen verfügbar und diese dadurch resilienter zu machen, wurde im kürzlich erfolgreich beendeten, DIZH-geförderten Projekt AUTODIDACT ein Objekterkennungssystem entwickelt, das Kontextinformationen aus Videodaten extrahieren kann. Videodaten die auf der NIPS, wie auf vielen modernen Intensivstationen, bereits heute zur Verfügung stehen, da auf diesen Stationen Patienten standardmässig mit Kameras überwacht werden.
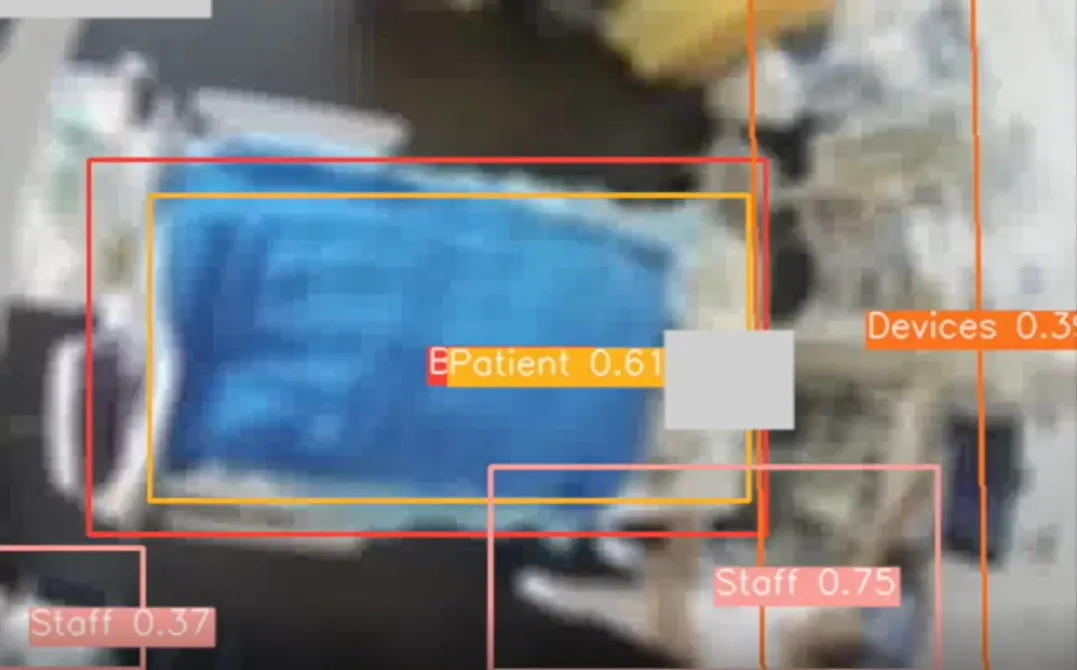
Als Kontextinformation wurde zu Beginn des Projekts die Erkennung des Bettes, des Patienten sowie des Pflegepersonals und der medizinischen Geräte definiert. Zum Schutz der Privatsphäre der Patienten und des medizinischen Personals musste die Objekterkennung auf unscharfen Videos basieren. Dies hatte zur Folge, dass ein ganz neues Objekterkennungsmodell entwickelt werden musste, da bereits trainierte Künstliche Intelligenz (KI) Systeme zur Objekterkennung nur für hoch aufgelöste Bilder verfügbar waren.
Hierzu wurden zuerst mit dem Einverständnis von Patienten unscharfe Videodaten als Trainingsdaten aufgezeichnet und in diesen durch Menschen annotiert. Basierend auf diesen Videos wurde dann in einem ersten Ansatz ein YOLOv5 Modell (ein KI-System für Objekterkennung, das als Quasi-Industriestandard gilt) trainiert, um eine Baseline zu etablieren. Die Objekterkennung geschieht bei diesem Ansatz auf Basis einzelner Bilder. Obschon die Erkennung für unscharfe Bilder relativ gut war, konnte diese in einem zweiten Ansatz weiter verbessert werden: Die Verbesserung wurde durch das Mitberücksichtigen des zeitlichen Verlaufs über mehrere Bilder hinweg erreicht. Dazu wurden die drei Inputkanäle Blau, Rot, Grün des YOLOv5-Modells durch andere Bildinformation ausgetauscht. Der rote Kanal wurde mit dem Schwarzweissbild ersetzt, der grüne mit den Pixelveränderungen zwischen dem vorhergehenden Bild und der blaue mit den Positionen der vorher detektierten Objekte. Dieser “Trick” resultierte dann in einem Modell, dass sich zum einen viel schneller trainieren liess und zum anderen insgesamt stabilere und genauere Resultate lieferte, was auch den begrenzten Hardwareressourcen zugutekam.